





































ВВЕДЕНИЕ
В настоящее время во всем мире проблема профилактики неблагоприятного воздействия факторов окружающей среды на здоровье человека привлекает внимание многих ученых – врачей, экологов, биологов, физиков. Это вызвано постоянным ростом числа факторов, оказывающих негативное воздействие на здоровье человека. По данным Всемирной организации здравоохранения (ВОЗ) около 1,4 млн. случаев преждевременной смерти могут быть связаны с экологическими факторами, причем 569 тыс. из них связаны с загрязнением окружающего воздуха, а 154 тыс. – с загрязнением воздуха внутри помещений [1]. Однако информация по оценке влияния многочисленных факторов среды помещения и окружающей среды на здоровье человека характеризуется рассеянностью, не позволяя учитывать все факторы в комплексе. Цифровые решения могут быть эффективным инструментом для анализа этих факторов и разработки научного обоснования влияния их на здоровье человека [2].
Анализ комплексной оценки влияния факторов окружающей среды на здоровье человека можно провести методом корреляции показателей здоровья населения по классам основных нозологий на определенной территории с показателями факторов окружающей среды на этой территории. Для этого возможно использование информационных технологий анализа данных, установления причинно-следственных связей изменения показателей здоровья населения с показателями факторов окружающей среды, оценки рисков их воздействия на здоровье. Полученные результаты могут использоваться для разработки профилактических мероприятий, направленных на уменьшение отрицательного влияния факторов среды на здоровье человека.
В статье собран и обработан материал по формированию модели практического применения результатов цифровых решений анализа оценки влияния факторов окружающей среды на здоровье населения.
МАТЕРИАЛЫ И МЕТОДЫ
Авторами был проведен анализ научных статей по теме исследования в общедоступных электронных базах Medline, PubMed, Google Scholar, Elibrary, по указанным ключевым словам, отчетам и докладам государственных органов, показателям Росстата. Использованы методы: структурный анализ; корреляционный анализ, метод ансамблевого машинного обучения, в частности дерево решения и алгоритм случайного леса.
Цель работы: предложить алгоритм прогнозирования воздействия комплекса факторов окружающей среды.
РЕЗУЛЬТАТЫ
В настоящее время в научной литературе предлагаются разные подходы оценки влияния факторов окружающей среды на здоровье населения [3-5]. В большинстве случаев они основываются на вероятностном математико-статистическом анализе воздействия вредного фактора на здоровье населения, с помощью которого можно количественно оценить уровень связи между факторами риска и критериями общественного здоровья и построить вероятностную математическую модель воздействия вредного фактора на здоровье населения [3, 4]. Количественная оценка риска может осуществляться с помощью корреляционного анализа. По коэффициентам корреляций можно судить о связи между загрязнением среды и состоянием здоровья населения [3].
Однако рост уровня заболеваемости населения, связанный с воздействием вредных факторов окружающей среды, может не носить линейный характер, так как пороги чувствительности и реакция защитных сил организма индивидуальны. Поэтому на начальном этапе воздействие вредных факторов может не отражаться на статистике заболеваемости или отражаться незначительно. При возрастающем воздействии в дальнейшем происходит срыв механизмов адаптации, и заболеваемость возрастает. Поэтому степень вредных воздействий факторов можно установить только на основании закона больших чисел – количественные закономерности массовых явлений проявляются лишь в достаточно большом их числе. Для этих целей необходимо выполнить анализ больших по численности групп населения. В небольших группах выводы могут быть ошибочные, так как большую роль будут играть случайные факты и индивидуальные особенности организма человека. При анализе большого количества событий случайности сглаживаются, и погрешности результатов снижаются [6].
Клепиковым О.В. и Студеникиной Е.М. предложены методы оценки влияния загрязнения атмосферного воздуха на здоровье населения при помощи анализа больших чисел. За величину, характеризующую загрязнённость атмосферы принимается комплексный индекс загрязнения атмосферы (ИЗА), учитывающий несколько приоритетных загрязнителей (как правило – пять) [1]. По значению коэффициента парной корреляции можно судить о тесноте взаимосвязи между изучаемыми показателями. Построение регрессионных моделей в таких исследованиях позволяет оценить направленность, силу, вид связи, прогнозировать значения. Моделировать процессы можно как по отдельным компонентам, так и в комплексе [3].
При оценке взаимосвязи здоровья населения с загрязнением окружающей среды часто используется линейное программирование. Для прогноза периодических процессов по известному спектру частот используется Фурье-анализ. Методы моделирования и прогнозирования временных рядов позволяют выявить тенденции изменения фактических значений параметра во времени и прогнозировать его будущие значения [3].
Коротковым П.А., Трубяновым А.Б. и соавт. для анализа статистической связи показателей загрязнения окружающей среды с показателями экологически зависимой заболеваемости предложена методология исследования, основанная на подходах к корреляционно-регрессионному анализу панельных данных. Для этого рассчитываются коэффициенты корреляции Пирсона и ранговые коэффициенты корреляции Спирмена, затем строятся модели регрессии для панельных данных: модель с фиксированными эффектами и модель со случайными эффектами. Источниками панельных данных являются показатели подразделений Росстата, Роспотребнадзора и Минздрава: 6 основных показателей загрязнения воды и атмосферы и 7 приоритетных показателей заболеваемости населения за определенный период (несколько лет) [4].
В рассматриваемых выше методиках данные о заболеваемости населения принимаются по статистическим данным. Однако для более углубленного анализа влияния негативных факторов окружающей среды на здоровье необходимо изучение показателей здоровья конкретной местности. Для этих целей можно воспользоваться единой интегрированной платформой, на которую будут поступать от медицинских учреждений все данные о здоровье пациентов. Благодаря таким данным можно проводить детальный анализ влияния факторов среды на здоровье, учитывающий и наличие загрязняющих веществ в организме пациентов, и их ответную реакцию на изменение факторов среды. Хранение больших данных можно обеспечить в облачных хранилищах.
На основе изученных материалов и методик анализа больших данных в данной работе мы в качестве примеров выполнили:
- корреляционный анализ и прогноз показателей загрязнения атмосферного воздуха и заболеваемости детей от 0 до 14 лет по болезням органов дыхания по Волгоградской области за пять лет – с 2018 по 2022 гг.;
- алгоритм прогнозирования воздействия комплекса факторов окружающей среды.
Корреляционный анализ и прогноз показателей загрязнения атмосферного воздуха и заболеваемости детей от 0 до 14 лет по болезням органов дыхания по Волгоградской области за пять лет – с 2018 по 2022 гг.
Исследованием комплексной гигиенической оценки факторов окружающей среды, проведенным Клепиковым О.В. и др. на основе города Воронежа, установлено, что приоритетным фактором неблагоприятного воздействия на здоровье населения является атмосферный воздух [7].
Индекс загрязнения атмосферного воздуха (ИЗА) по пяти приоритетным загрязнителям принят по статистическим данным, приведенным в Докладе Комитета природных ресурсов, лесного хозяйства и экологии Волгоградской области о состоянии окружающей среды Волгоградской области в 2022 году [8]. Влиянию вредных факторов окружающей среды наиболее подвержены дети. Важно, что дети более привязаны к исследуемой территории, так как в основном они живут и учатся на одном территориальном участке, на их здоровье не отражаются профессиональные факторы. Все это уменьшает величину случайных событий при анализе данных, поэтому предлагается проводить анализ статистических данных о заболеваемости детей по основным нозологиям. Показатели заболеваемости детей приняты по данным Росстата и Роспотребнадзора по Волгоградской области [9-14]. В заболеваниях органов дыхания учитываются: бронхиты, пневмонии, бронхиальная астма, хроническая обструктивная болезнь легких, бронхоэктатическая болезнь, плеврит, эмфизема легких. По данным проведенных исследований прослеживается взаимосвязь этих заболеваний с такими загрязнителями воздуха: взвешенные вещества, диоксид азота, бензапирен [15, 16]. В таблице 1 приведены показатели ИЗА и заболеваемости, на основании которых произведены расчеты.
Значение коэффициента корреляции (R) может быть: -1 < R < +l, что свидетельствует:
- R близко к 0 – свидетельствует об отсутствии корреляционной связи между концентрациями вредных веществ и уровнем заболеваемости;
- R близко к 1 – существует положительная связь;
- R близко к -1 – существует отрицательная связь.
Таблица 1. Показатели ИЗА и болезней органов дыхания по Волгоградской области за 2018-2022 гг.
Table 1. Indicators of IZA and respiratory diseases in the Yolgograd region for 2018-2022
| Годы | Болезни органов дыхания (Волгоград) (на 100 тыс. детского населения) | ИЗА (Волгоград) |
|---|---|---|
| 2018 | 115191,80 | 4,30 |
| 2019 | 113388,70 | 3,20 |
| 2020 | 105602,60 | 3,50 |
| 2021 | 115278,10 | 10,60 |
| 2022 | 122320,00 | 10,60 |
Анализ с применением электронных таблиц Microsoft Excel приведен на гистограмме (рис. 1). Коэффициент корреляции, рассчитанный по формуле в электронной таблице Microsoft Excel равен 0,70, что свидетельствует о наличии положительной зависимости.
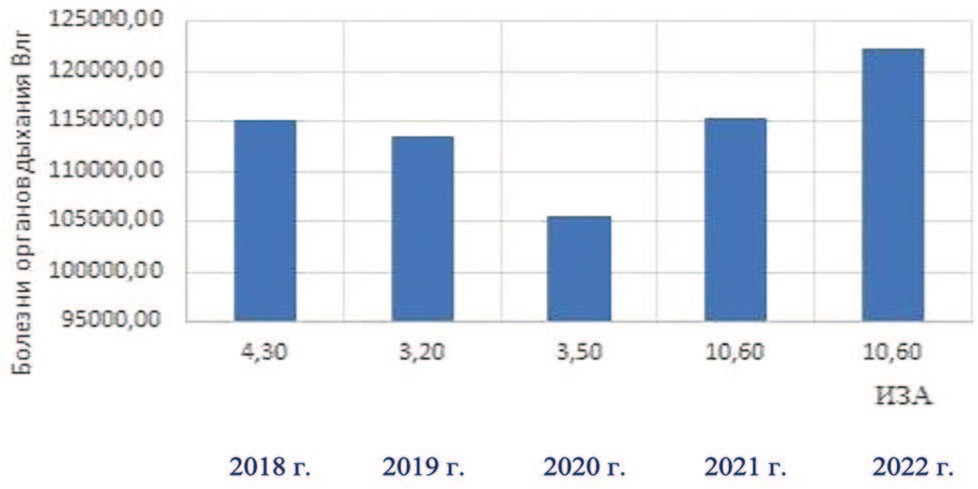
Рис.1 Вероятностная взаимосвязь между уровнем загрязнения атмосферного воздуха и уровнем заболеваемости органов дыхания по Волгоградской области за 2018 – 2022 гг. (расчет по формуле корреляции в электронной таблице Microsoft Excel) (выполнено авторами)
Fig.1 Probabilistic relationship between the level of atmospheric air pollution and the level of respiratory morbidity in the Volgograd region for 2018 – 2022. (calculation using the correlation formula in a Microsoft Excel spreadsheet) (completed by the authors)
На основе данных таблицы 1 с помощью электронной таблицы Microsoft Excel был сделан график и построена линия тренда (аппрок-симирующая функция y(x), которая с максимальной степенью близости приближается к опытной зависимости) (рис. 2).
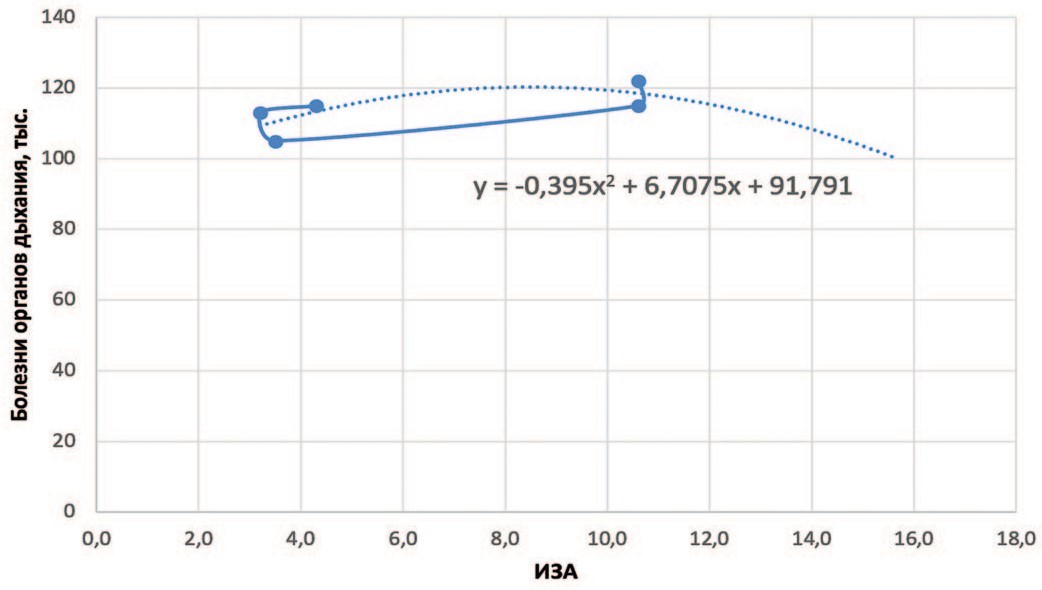
Рис.2. График зависимости между уровнем загрязнения атмосферного воздуха и уровнем заболеваемости органов дыхания и линия тренда (выполнено авторами)
Fig.2. Graph of the relationship between the level of atmospheric air pollution and the level of respiratory diseases and the trend line (completed by the authors)
Как видно на рисунке, зависимость не является линейной.
Прогноз воздействия загрязнения атмосферного воздуха на болезни органов дыхания выполнен в облачном сервисе Google Collab. В качестве исследования была выбрана задача прогнозирования возникновения заболевания одной из групп у человека при известных числовых показателях ИЗА, взятых из официальных источников по Волгоградской области, представленных в таблице 1.
Предлагается применить метод ансамблевого машинного обучения в виде алгоритма случайного леса и дерева решений на примере набора данных с помощью языка программирования Python, где в качестве признаков будут использоваться числовые показатели индекса загрязнения атмосферы, а в качестве целевой переменной — группы болезней органов дыхания. Random forest («Случайный лес») – алгоритм машинного обучения, заключающийся в использовании комитета (ансамбля) решающих деревьев [17-19]. Ниже приведена ссылка, в которой мы реализовали метод алгоритма случайного леса.
https://colab.research.google.com/drive/1p4ozfSrOPl2AzUONwlVSZrmYzTvCtiDw?usp=sharingПриводим пример написания кода:
- прогноз обучающей модели (рис. 3):
Рис. 3. Прогноз обучающей модели (выполнено авторами)
Fig. 3. The forecast of the training model (completed by the authors) - построение дерева решений (рис. 4):

Рис. 4. Построение дерева решений (выполнено авторами)
Fig. 4. Building a decision tree (completed by the authors) - проверка прогноза (рис. 5):
Рис. 5. Проверка прогноза (выполнено авторами)
Fig. 5. Checking the forecast (completed by the authors)
Вывод диаграммы вероятностной зависимости между уровнем загрязнения атмосферного воздуха и уровнем заболеваемости органов дыхания показывает наличие зависимости, однако она не является линейной (рис. 6):
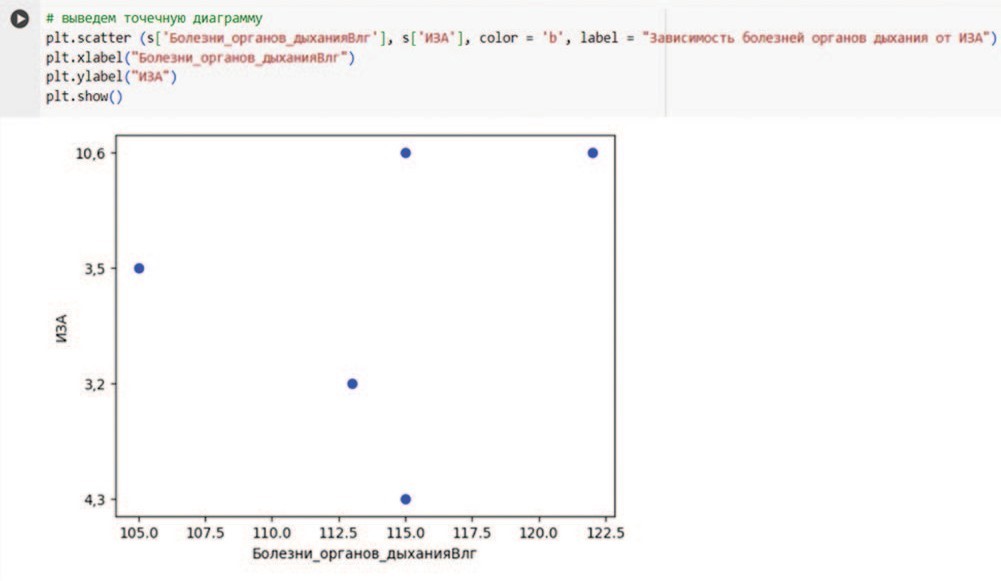
Рис. 6. Проверка прогноза (выполнено авторами)
Fig. 6. Checking the forecast (completed by the authors)
Алгоритм прогнозирования воздействия комплекса факторов окружающей среды
В качестве исследования была выбрана задача прогнозирования возникновения заболевания одной из групп у человека при известных числовых показателях воздействия окружающей среды.
Предлагается применить метод ансамблевого машинного обучения в виде алгоритма случайного леса и дерева решений на примере набора данных с помощью языка программирования Python, где в качестве признаков будут использоваться числовые показатели воздействия различных факторов на организм человека, а в качестве целевой переменной – группы болезней, которые могут возникнуть [20].
Дерево решений – это структура данных, которая представляет собой древовидную модель принятия решений в виде логических правил. Каждый узел дерева представляет собой признак, по которому происходит разделение данных, а каждое ребро – условие (например, «больше 30 лет»). Листовые узлы дерева содержат предсказание (например, класс объекта).
Процесс построения дерева решений включает следующие этапы:
- Выбор признака для разделения дерева на узлы: На каждом узле дерева выбирается признак, который наилучшим образом разделяет данные на подгруппы. Этот выбор осуществляется на основе критерия информативности.
- Разделение данных: После выбора признака происходит разделение данных на две или более подгруппы в зависимости от значения выбранного признака.
- Построение поддеревьев: Для каждой подгруппы данных происходит рекурсивное построение поддерева, повторяя процесс выбора признака и разделения данных.
- Остановка построения дерева: Построение дерева может быть остановлено при достижении определенного критерия, например, максимальной глубины дерева, минимального числа объектов в листе или при отсутствии улучшения качества разделения.
Деревья решений могут быть склонны к переобучению, поэтому модель случайного леса использует несколько деревьев для уменьшения этого эффекта. Каждое дерево обучается на случайной подвыборке данных и случайном подмножестве признаков, что способствует разнообразию деревьев и повышению качества модели.
В качестве параметров были выбраны следующие факторы: уровни взвешенных веществ, оксида углерода, диоксида азота, диоксида серы и оксида азота в атмосферном воздухе, нитратов, ртути, бензола, марганца, свинца в почве, а также уровни железа, меди, цинка и фенола в водопроводной воде, уровень радиоактивной нагрузки. В качестве предсказываемых классов рассматриваются заболевания органов дыхания, заболевания печени и почек, онкологические заболевания, сердечно-сосудистые заболевания, отсутствие заболеваний. Ниже приведена реализация алгоритма случайного леса:
Загрузка необходимых библиотек:
- from sklearn.ensemble import Random- ForestClassifier
- from sklearn.model_selection import train_test_split
- from sklearn.metrics import accuracy_score
Далее разделяем данные на обучающий и тестовый наборы, здесь X – параметры воздействия окружающей среды, Y – величина, принадлежащая к одному из классов: заболевание органов дыхания, заболевание печени и почек, онкологическое заболевание, сердечно-сосудистое заболевание, отсутствие заболеваний.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42
Инициализация и обучение модели Random Forest:
clf = RandomForestClassifier()
clf.fit(X_train, y_train)
Предсказание на тестовом наборе: y_pred = clf.predict(X_test)
Оценка качества модели:
accuracy = accuracy_score(y_test, y_pred) print("Accuracy:", accuracy)
На основе посчитанных моделью весов можно сделать выводы о том, какие факторы наиболее существенно влияют на возникновения тех или иных заболеваний. Получить веса можно с помощью приведенного ниже кода:
importances = clf.feature_importances_
for class_idx, class_name in enumerate (clf.classes_):
print(f"Class: {class_name}")
for idx, importance in enumerate(importances[class_idx]):
print(f"Feature {idx}: Importance {importance}") print("\n")
ОБСУЖДЕНИЕ
Изучение собранных материалов и проведенный анализ на примере Волгоградской области показал, что имеется вероятностная зависимость между уровнем загрязнения атмосферного воздуха и уровнем заболеваемости органов дыхания среди детского населения, однако она не является линейной.
По расчетам в электронной таблице Microsoft Excel значение коэффициента корреляции равно 0,7 что свидетельствует о наличии положительной зависимости между уровнем загрязнения атмосферного воздуха и уровнем заболеваемости органов дыхания, не являющейся линейной (рис. 2), В облачном сервисе Google Collab с помощью метода лесов можно сделать прогноз и его оценку, а также построить точечную диаграмму зависимостей. Мы видим, что в обеих цифровых технологиях существует положительная связь между факторами загрязнения атмосферного воздуха и болезнями органов дыхания.
Для прогнозирования воздействия комплекса факторов окружающей среды на здоровье населения предлагается применить метод ансамблевого машинного обучения в виде алгоритма случайного леса и дерева решений на примере набора данных с помощью языка программирования Python, где в качестве признаков будут использоваться числовые показатели воздействия различных факторов на организм человека, а в качестве целевой переменной – группы болезней, которые могут возникнуть.
Для обучения модели возможно применение баз данных на основе мониторинга факторов прошлых лет. Подойдут данные с разных инфраструктурных территорий страны и рассмотрением различных показателей. Уже к обученной модели можно подключать как большие объёмы, такие как анализ состава воздуха по городу, так и локальные, собранные непосредственно в исследуемом помещении.
Существуют обновляемые в реальном времени базы данных, которые позволяют проводить операции ввода/изменения данных и получать актуальные результаты немедленно. Примерами таких баз данных являются Apache Kafka, Amazon DynamoDB, Google Firebase Realtime Database и другие. Эти базы данных позволяют мгновенно обновлять информацию и реагировать на изменения в реальном времени. Именно одну из таких можно использовать для прогнозирования и мониторинга зависимости.
В качестве сбора данных можно использовать различные датчики и анализаторы, обслуживание которых будет быстрым и простым. Для удобства и упрощения на каждый фактор можно завести отдельный датчик, передающий информацию в обновляемую базу данных.
ВЫВОДЫ
- Для исследования зависимостей уровня заболеваемости от факторов окружающей среды можно использовать различные виды цифровых моделей.
- Степень воздействия вредных факторов окружающей среды можно установить только на основании закона больших чисел, так как количественные закономерности массовых явлений проявляются лишь в достаточно большом их числе [20-26].
- Корреляционный анализ показателей загрязнения атмосферного воздуха и заболеваемости детей от 0 до 14 лет по болезням органов дыхания по Волгоградской области за пять лет, проведенный по двум цифровым технологиям, показывает наличие положительной связи между факторами загрязнения атмосферного воздуха и болезнями органов дыхания. Однако эта зависимость не является линейной.
- Для комплексной оценки факторов окружающей среды на здоровье человека нами предлагается применить модель случайного леса машинного обучения на наборе данных факторов окружающей среды. На основе посчитанных моделью весов можно сделать выводы о том, какие факторы наиболее существенно влияют на возникновения тех или иных заболеваний.
- Преимущество цифровой платформы сбора и обработки данных перед отдельными модулями в том, что она позволяет осуществить в одном месте все показатели региона, выполнить анализ данных, автоматически сообщать сигналы, где возникают риски негативного воздействия на здоровье.
